



(nb: I make frequent references to the Smogon's tiering article. Just mentioning this on the off-chance that you're reading this and somehow you're not aware of that article.)
Hey, all. Since Super is apparently trying to get usage stats to work this weekend, I thought that I should bring up something that I've been wanting to bring up for a long time. Coyotte's thread was similar, but it kind of trivialized the issue of how to make the cutoff and it was never really resolved. This post intends to change that. I was originally going to have this be a series of threads where the underusage cutoff formula was constructed step by step, but I eventually thought it best to lay everything out in this thread and then maybe have polls for each step or something.
I'm bringing this up because it seems to me as if we're heading toward accepting a simple x% cutoff because that's what Coyotte is using. Besides my personal disagreement with this method, I feel that we'd be taking steps backward and nullifying the efforts of people who have discussed this in the past, like X-Act, obi, DougJustDoug and Cathy, if we didn't take a serious look at what has been used in the past, what may be used in the immediate future, and what we as a community really want out of the cutoff. I also understand that this may not seem to be the best time to talk about this, but I don't see us talking about much else right now, and I'm hoping to get all this decided before we get the hard numbers.
I also intend to give and explain formulas for each aspect of the cutoff, at least eventually, because I think that sometimes the explaining part was lacking in past discussions. Even if the calculations and explanations are "trivial" or "too technical", it's nice to have some kind of explanation around so that the constant in the tier philosophy page right now doesn't look so arbitrary. It also makes it easier on those of us who are looking for explanations for our running usage stats in the manner in which we are running them. I also wanted to give examples using maybe the August 2010 Shoddy stats as a sample, but to do that for every single formula that's going to be discussed seems not worth it at all. I may give examples if the options are shrunk down later on, though.
Step 0: A look at existing proposed cutoffs
From what I've seen, three main cutoffs have been proposed, and two have been put into use:
1. Coyotte's cutoff: x% cutoff
2. 4th gen cutoff: A Pokémon is OU if its probability of appearing in a random selection of T teams is at least x.) (T = 20 and x = 0.5 in actual usage)
3. Collective cutoff: OU is the collection of the most used Pokémon who together make up x of all teams.
I also saw something about comparing each Pokémon's usage with the #1 most used Pokémon's usage during my "research" into past discussions.
I'll talk about each of these in later steps, but I wanted to highlight here the current displayed formula for the 4th gen cutoff:
S is the sum of all of the usages, being used presumably due to error in the data collection causing S to be a bit different from 1. I'm going to ignore S for simplicity's sake.
I don't quite understand why the cutoff is divided by 6. The fact that there are six Pokémon on a team shouldn't factor into the formula at all, due to Species Clause. However, the rest checks out:
Let u be the usage of a Pokémon. Then the probability that it won't appear in a random selection of T teams is (1 - u)^T. We want this to equal 1 - x when u = C, so C = 1 - (1 - x)^(1/T).
When T = 20 and x = 0.5, we get 3.41%, which if I'm not mistaken is near what we used last generation, anyway. There's also a prediction factor involved, but I'll talk about that in a later step.
Step 1: The purpose of tiers: individual vs collective merit
The way I see it, there are two primary motivations to make UU (and NU and such). The first is to make a "low-tier" game where Pokémon who are used at a certain frequency are banned; this ties into individual merit. The second is to create an accurate threat list that accounts for everything that a typical team might have; this ties into collective merit. The first two cutoffs address the former, while the collective cutoff addresses the latter.
Both individual and collective merit based cutoffs have their advantages and disadvantages. By setting a hard percentage cutoff, one essentially ensures that only "not uncommon" Pokémon are in OU, but a threat list composed of the OUs has inconsistent accuracy and relevance. On the other hand, by setting a collective cutoff, one is able to control how accurate the OU threat list is, at the cost of possibly letting "rare" Pokémon into the OU tier.
There are two ways that I can think of to calculate a collective cutoff. The first is the cutoff 3. listed above.
"OU is the smallest collection of the most used Pokémon who together make up at least x of all teams."
Equivalently, UU is the largest collection of the least used Pokémon from which none are in less than x of all teams. That means that (if N is the total number of Pokémon) #N doesn't appear AND #N-1 doesn't appear AND etc.:
The goal is to find the lowest n for which P(n) >= x. Unfortunately, there's no "formula" for this cutoff simply because of the nature of how it's calculated, but with a few estimates it shouldn't be too bad after a few iterations of doing this.
EDIT: I think that I made the rookie mistake of assuming that I'd set this up so that correlation didn't matter. It does. Sorry about that.
The other method is a slight modification:
"OU is the smallest collection of the most used Pokémon from which at least one is present in at least x of all teams."
Then the formula becomes P(n) = product(i=1,n-1)(u_i). The advantage of this becomes clear when we look at the likely values of x. With the first formula, we may be looking at something like 50%, while with this formula, that number could be more like 95%. To say that the OU threat list is 95% accurate is pretty appealing. Nonetheless, this may be a less accurate way to interpret what we want out of a threat list in the first place, since we seek to deal with teams, not individual Pokémon.
Step 2: Sample size
With sample size, we're essentially looking at the phrase, "random selection of T teams." For Coyotte's cutoff, the sample size T is the entire population, while for X-Act's cutoff, T is obviously 20. Now, I personally don't find the use of the entire population very useful at all, since in the end (I'm presuming) we're trying to appeal to an individual's experiences of what is common/rare and what is not common/rare. On the other hand, if we use the collective cutoff in Step 1, the OU definition might get just a little bit complicated:
"OU is the smallest collection of the most used Pokémon for which the probability that they fully make up at least t out of a random selection of T teams is at least x."
I hope you'll forgive me for not deriving a formula for this :P
One should note that, regardless of which cutoff we use, we're actually deciding two things here: the sample size T and the ratio t/T. Technically, there's no reason not to have picked "2 in 40 teams" or "3 in 60 teams" in X-Act's cutoff other than sheer simplicity. It's something to keep in mind if anyone wants something like "3 in 10 teams". In cases like this, we'll have to call upon the binomial distribution:
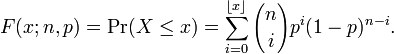
One would have to solve for 1 - p to get the cutoff C in this case. "Sheer simplicity" is looking like a very valid argument right now...
Personally, I think that, given we stick with the 4th gen cutoff, we should get a stat showing the average number of battles that a user participates in in a day, and determine T by that. t should be 1 because I don't think anyone wants to invert that huge formula I copy-pasted from Wikipedia.
Step 3: Predictive tiering and weighted stats
I consider this an extremely important step. A tier list arising from present usage stats is, in fact, obsolete right out of the box. But here's where things get vague as far as research into the past discussions of this matter goes.
First, the weighted stats. Apparently, X-Act had originally used ratios related to the Golden Ratio instead of the 20-3-1 ratio used today, but I'm guessing that he went with 20-3-1 for simplicity's sake. The point of the weighted stats is to use the usage stats from every "checkpoint" (that is, every time the stats are drawn) in such a way that more recent checkpoints have more impact than less recent ones do. There isn't much that I could find on this stuff, but for the most part this seems uncontroversial.
The real puzzling matter is stat prediction. There was discussion on it, but I'm not sure that it ever got implemented. Either that or it was scrapped. I wanted to bring this back up because I wanted to see if people could come up with a way to predict stats that would help to make the tier list more relevant to the present. Ideally, I'd want to use polynomial fitting, but in practice that would probably take way too much effort.
---
Well, my hope for this post was to demystify (at least a little bit) the usage cutoff methods that have been used, as well as a few that were discussed but never got off the ground. Even if most people end up not understanding much of it, I thought that it would be very important to have a compendium of sorts so that people don't have to dig through PR, IS, even Stark Mountain to understand the tier list that we hold so dearly. I also wanted to lay everything out so that people wouldn't feel as disadvantaged when trying to support one method or propose an entirely different method. Finally, even if people just want the status quo of X-Act's cutoff or Coyotte's cutoff or whatever, I'd feel a lot better knowing that you guys have a better idea of what exactly sticking to the status quo would entail.
"wtf" is an entirely appropriate reaction, too; I wouldn't blame you
Hey, all. Since Super is apparently trying to get usage stats to work this weekend, I thought that I should bring up something that I've been wanting to bring up for a long time. Coyotte's thread was similar, but it kind of trivialized the issue of how to make the cutoff and it was never really resolved. This post intends to change that. I was originally going to have this be a series of threads where the underusage cutoff formula was constructed step by step, but I eventually thought it best to lay everything out in this thread and then maybe have polls for each step or something.
I'm bringing this up because it seems to me as if we're heading toward accepting a simple x% cutoff because that's what Coyotte is using. Besides my personal disagreement with this method, I feel that we'd be taking steps backward and nullifying the efforts of people who have discussed this in the past, like X-Act, obi, DougJustDoug and Cathy, if we didn't take a serious look at what has been used in the past, what may be used in the immediate future, and what we as a community really want out of the cutoff. I also understand that this may not seem to be the best time to talk about this, but I don't see us talking about much else right now, and I'm hoping to get all this decided before we get the hard numbers.
I also intend to give and explain formulas for each aspect of the cutoff, at least eventually, because I think that sometimes the explaining part was lacking in past discussions. Even if the calculations and explanations are "trivial" or "too technical", it's nice to have some kind of explanation around so that the constant in the tier philosophy page right now doesn't look so arbitrary. It also makes it easier on those of us who are looking for explanations for our running usage stats in the manner in which we are running them. I also wanted to give examples using maybe the August 2010 Shoddy stats as a sample, but to do that for every single formula that's going to be discussed seems not worth it at all. I may give examples if the options are shrunk down later on, though.
Step 0: A look at existing proposed cutoffs
From what I've seen, three main cutoffs have been proposed, and two have been put into use:
1. Coyotte's cutoff: x% cutoff
2. 4th gen cutoff: A Pokémon is OU if its probability of appearing in a random selection of T teams is at least x.) (T = 20 and x = 0.5 in actual usage)
3. Collective cutoff: OU is the collection of the most used Pokémon who together make up x of all teams.
I also saw something about comparing each Pokémon's usage with the #1 most used Pokémon's usage during my "research" into past discussions.
I'll talk about each of these in later steps, but I wanted to highlight here the current displayed formula for the 4th gen cutoff:
X-Act said:C = S x (1 - (0.5)^(1 / T)) / 6
S is the sum of all of the usages, being used presumably due to error in the data collection causing S to be a bit different from 1. I'm going to ignore S for simplicity's sake.
I don't quite understand why the cutoff is divided by 6. The fact that there are six Pokémon on a team shouldn't factor into the formula at all, due to Species Clause. However, the rest checks out:
Let u be the usage of a Pokémon. Then the probability that it won't appear in a random selection of T teams is (1 - u)^T. We want this to equal 1 - x when u = C, so C = 1 - (1 - x)^(1/T).
When T = 20 and x = 0.5, we get 3.41%, which if I'm not mistaken is near what we used last generation, anyway. There's also a prediction factor involved, but I'll talk about that in a later step.
Step 1: The purpose of tiers: individual vs collective merit
The way I see it, there are two primary motivations to make UU (and NU and such). The first is to make a "low-tier" game where Pokémon who are used at a certain frequency are banned; this ties into individual merit. The second is to create an accurate threat list that accounts for everything that a typical team might have; this ties into collective merit. The first two cutoffs address the former, while the collective cutoff addresses the latter.
Both individual and collective merit based cutoffs have their advantages and disadvantages. By setting a hard percentage cutoff, one essentially ensures that only "not uncommon" Pokémon are in OU, but a threat list composed of the OUs has inconsistent accuracy and relevance. On the other hand, by setting a collective cutoff, one is able to control how accurate the OU threat list is, at the cost of possibly letting "rare" Pokémon into the OU tier.
There are two ways that I can think of to calculate a collective cutoff. The first is the cutoff 3. listed above.
"OU is the smallest collection of the most used Pokémon who together make up at least x of all teams."
Equivalently, UU is the largest collection of the least used Pokémon from which none are in less than x of all teams. That means that (if N is the total number of Pokémon) #N doesn't appear AND #N-1 doesn't appear AND etc.:
The goal is to find the lowest n for which P(n) >= x. Unfortunately, there's no "formula" for this cutoff simply because of the nature of how it's calculated, but with a few estimates it shouldn't be too bad after a few iterations of doing this.
EDIT: I think that I made the rookie mistake of assuming that I'd set this up so that correlation didn't matter. It does. Sorry about that.
The other method is a slight modification:
"OU is the smallest collection of the most used Pokémon from which at least one is present in at least x of all teams."
Then the formula becomes P(n) = product(i=1,n-1)(u_i). The advantage of this becomes clear when we look at the likely values of x. With the first formula, we may be looking at something like 50%, while with this formula, that number could be more like 95%. To say that the OU threat list is 95% accurate is pretty appealing. Nonetheless, this may be a less accurate way to interpret what we want out of a threat list in the first place, since we seek to deal with teams, not individual Pokémon.
Step 2: Sample size
With sample size, we're essentially looking at the phrase, "random selection of T teams." For Coyotte's cutoff, the sample size T is the entire population, while for X-Act's cutoff, T is obviously 20. Now, I personally don't find the use of the entire population very useful at all, since in the end (I'm presuming) we're trying to appeal to an individual's experiences of what is common/rare and what is not common/rare. On the other hand, if we use the collective cutoff in Step 1, the OU definition might get just a little bit complicated:
"OU is the smallest collection of the most used Pokémon for which the probability that they fully make up at least t out of a random selection of T teams is at least x."
I hope you'll forgive me for not deriving a formula for this :P
One should note that, regardless of which cutoff we use, we're actually deciding two things here: the sample size T and the ratio t/T. Technically, there's no reason not to have picked "2 in 40 teams" or "3 in 60 teams" in X-Act's cutoff other than sheer simplicity. It's something to keep in mind if anyone wants something like "3 in 10 teams". In cases like this, we'll have to call upon the binomial distribution:
One would have to solve for 1 - p to get the cutoff C in this case. "Sheer simplicity" is looking like a very valid argument right now...
Personally, I think that, given we stick with the 4th gen cutoff, we should get a stat showing the average number of battles that a user participates in in a day, and determine T by that. t should be 1 because I don't think anyone wants to invert that huge formula I copy-pasted from Wikipedia.
Step 3: Predictive tiering and weighted stats
I consider this an extremely important step. A tier list arising from present usage stats is, in fact, obsolete right out of the box. But here's where things get vague as far as research into the past discussions of this matter goes.
First, the weighted stats. Apparently, X-Act had originally used ratios related to the Golden Ratio instead of the 20-3-1 ratio used today, but I'm guessing that he went with 20-3-1 for simplicity's sake. The point of the weighted stats is to use the usage stats from every "checkpoint" (that is, every time the stats are drawn) in such a way that more recent checkpoints have more impact than less recent ones do. There isn't much that I could find on this stuff, but for the most part this seems uncontroversial.
The real puzzling matter is stat prediction. There was discussion on it, but I'm not sure that it ever got implemented. Either that or it was scrapped. I wanted to bring this back up because I wanted to see if people could come up with a way to predict stats that would help to make the tier list more relevant to the present. Ideally, I'd want to use polynomial fitting, but in practice that would probably take way too much effort.
---
Well, my hope for this post was to demystify (at least a little bit) the usage cutoff methods that have been used, as well as a few that were discussed but never got off the ground. Even if most people end up not understanding much of it, I thought that it would be very important to have a compendium of sorts so that people don't have to dig through PR, IS, even Stark Mountain to understand the tier list that we hold so dearly. I also wanted to lay everything out so that people wouldn't feel as disadvantaged when trying to support one method or propose an entirely different method. Finally, even if people just want the status quo of X-Act's cutoff or Coyotte's cutoff or whatever, I'd feel a lot better knowing that you guys have a better idea of what exactly sticking to the status quo would entail.
"wtf" is an entirely appropriate reaction, too; I wouldn't blame you














